In this, the next article of our Data Series, we move away from focussing on our normal perceptions of data and look at it from a different angle: semantics and meaningful information. Data can bring transformational value to a business if harnessed correctly and used in a meaningful way. In this article experts from Iotics talk about everything from data streaming to metadata and even trustworthiness.
Our Experts

Mark: I’m Mark Wharton, CTO of the Labs Division of Iotics and co-founder of what was Iotic labs and is now Iotics.

Ali: I’m Ali Nicholl. I lead engagement Iotics, which is a fancy way of saying I’m a cheerleader. And my job is to go out and work with our customers, partners and ecosystem to drive and share the story.
About Iotics
Mark: The company’s mission is to connect anything to anything.
We started life in the IoT space, a platform of platforms for the IoT. We then promptly pivoted to focusing on contextualising the rapidly growing amount of IoT data with other data in order for it all to make sense. Making sense of data, democratizing data and surfacing data so people can use it, is one of our main aims. Symmetry is also a big word in Iotics when it comes to actionable insights: If we’re trying to get to the level of using data to inform decisions and enable insights, why is it that people have to action insights? Why couldn’t it be AI or ML algorithms that action things as well? Consequently, we have a two-way approach in Iotics: If data can flow from left to right, so can the control information.
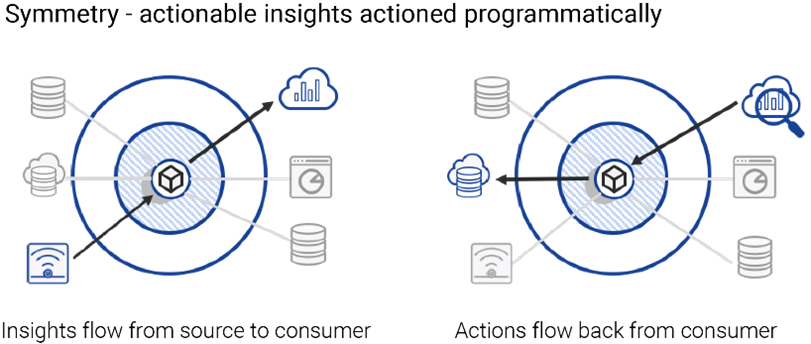
Ali: We need to help the world make better informed decisions.
Everyone has their own priorities and drivers, but they need to make the best informed decisions and that means taking data, contextualising the data with meaningful event information that matters to you, and then bringing them together from across your supply and demand chain, and from across your ecosystem, to augment and automate your decisions through the power of technology.
There are now so many facets to everything we do, its impractical to believe that there is any enterprise, government or organisation that can look at enough dashboards to synthesise all the relevant information. What’s more, in a post-COVID world, all the expertise we have on patterns of supply and demand have gone out the window. The world has changed and none of us are quite sure what the new patterns will be, so how do you bring all this information together and allow you to see trends?
As Co-Founder Mark, can you tell us about your background and how Iotics was born?
Mark: In 1983 I graduated with a physics degree from Durham. I ended up working in the Energy industry for four years as a programmer using the likes of Cobol. I then got a job working as a Trainer teaching people programming systems, databases designs, and transaction processing.
When the year 2000 came along, all of the work that I had teaching people dried up overnight so I got a job at mobile phone comms company called TTPCom, as I live near Cambridge which is famous for telecoms and embedded computing. It was a real eye-opener as I had been working on some of the biggest mainframe systems and Global networks, but as soon as someone explained how a mobile phone worked, I realised that the level of complexity of something that you hold in your hand is incredible.
With that weird background of knowing about data and knowing about mobile comms, I ended up in a Company called Arkessa who are virtual mobile network operator. That is where I met Paul, the Co-Founder of Iotics and we rebuilt Arkessa’s infrastructure together. Paul had always had this idea that he called “Second life for things”, where virtual versions of something could meet virtual versions of something else in a virtual space. And the idea for Iotics was born: Where you could have virtual versions of things meeting each other in this virtual space. It has taken 7-8 years to build something and to even figure out what it is! We call it an Event-Data Platform, but it has lots of other applications.
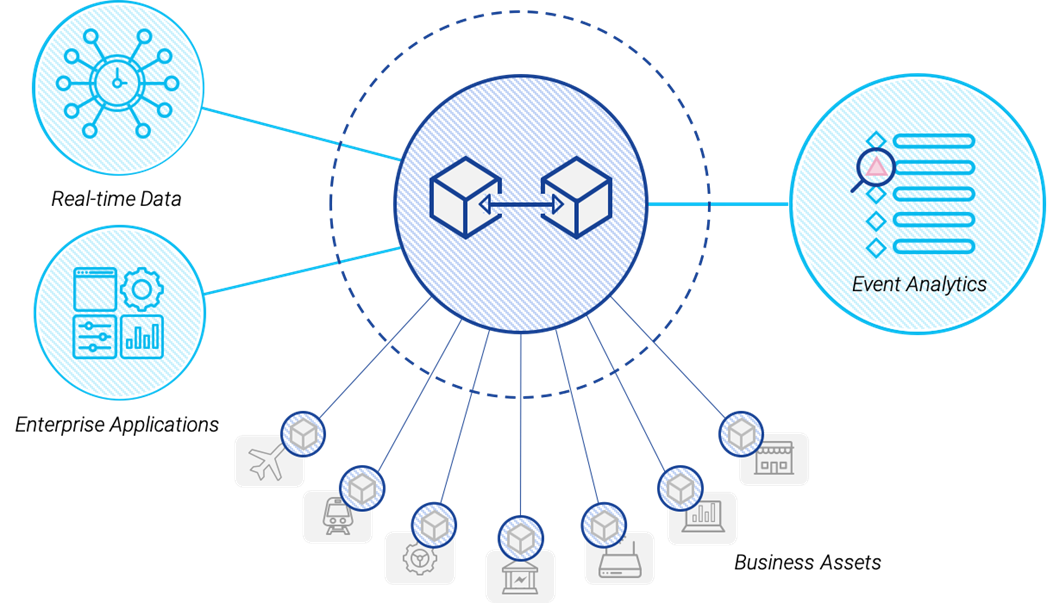
What have been some of the biggest challenges when it comes to connecting and accessing the devices or the data that you need to build your business upon?
Mark: The biggest challenges revolve around political, technical, and structural issues. One of the main challenges is that people do not like sharing their data. It is very much a “I’ll show you mine if you show me yours” mentality.
A good analogy is back when you were in primary school and someone stole your plimsolls (a.k.a daps or pumps) and they then stole yours, and then you would have to negotiate: I’ll give you your plimsolls back if you give me mine. There is this two-way interaction that people have that they’re natural with, but if somebody says “Do you want to share your data?” they get all uppity about it.
People are often told that their data has value. It’s the “new oil” etc. which makes it worse because they get more possessive about it. The story we tell them is: The ones that share are the ones that are going to be winning. This is my hunch for the 21st century. The sharers are the winners. People don’t like things which are sticky. I know a lot of manufacturers say if you wear Adidas trainers you should wear an Adidas tracksuit, but the world is not like that. People wear Adidas trainers because they’re comfortable and they like them, but they want to wear a Nike tracksuit.
What would you say have been some of the biggest technical challenges?
Mark: The big technical Challenge for us is that people think that static data is enough. They will give you static data in the most stupid forms: “This is a PDF of something thatwe made in 2014.” This is of no use to us: Where are the events? Where is the stuff happening? People are beginning to see the value of streaming data but it’s still a concept people struggle with. With data there is motion.

Another technical challenge is finding the data, interfacing to their data and being able to put things into corporate networks. A good example is in Demilitarized Zones where you’re interfacing into something on the left inside their private networks, hooking data out to the right, all whilst dealing with IT security policy politics as well.
However, one of the most important technical challenges we face is that people don’t careabout semantics. When we went to Rolls-Royce we met a guy whose job it was to work out what the engineers, who had installed the sensors, onto their big diesel engines had called things. It was up to themto decide whether to call it oil pressure or crankcase pressure, RPM or revolutionsor engine speed. And these names would be used randomly.
As a result, when the data came to us it had different column Headings along the top of it. One said crankcase pressure, onesaid oil pressure. No units were given, youhad to look that unit up. Now we’ve worked with Rolls-Royce to produce an ontology and I think that is quite forward sighted.
Leading on from that, another challenge is that people have their data, but they don’t know what it means. It’s normally so hidden from them that you can’t find it. You might see something on a web page that says name and address and then gives you the name and address, but if that name and address is called something completely bonkers in the database, how are you going to find it?
How would you explain Metadata to someone on the street?
Mark: When you mention the word “metadata” people just glaze over. I think people are getting used to it because the public understand that the sort of data Google, Apple and Amazon keep about them is more than just their name and address. We know they have information about your browsing history, the things that you like, the things that you buy and any other kind of activity which produces data about you. And I would therefore explain it around that: It’s about data about data. I know that sounds very meta, but then it is called metadata.
You’ve already mentioned the term Semantics. How would you describe that concept?
Mark: It is about meaning.
Right from the very beginnings of Iotics I thought: If we’re going to do this, we have to have some concepts of Semantics because if you want machine to machine interoperability, machines don’t understand Semantics. People do. You show somebody a picture of a dog they know it’s a dog. They know that dogs are furry. They know that dogs bark. They know dogs run and fetch twigs. They know a lot about dogs because they were taught it as they grew up as toddlers. Machines don’t have that toddler phase where they can learn, so you have to explain it to them.
The MET Office have a weather type which is just a number. Weather Type 1 is sunny, Weather Type 2 is rainy, Weather Type 3 is scattered showers etc. You can go to a website where there’s an HTML table which lists all of these types. I can do that as a human being, but what chance has a computer got about doing that?
Another example from the MET Office is Wind direction. How would you send a computer a wind direction? What format would you send a computer a wind direction in? The MET Office send you E and SE, or East and Southeast as compass points. How do you explain the compass point to a computer?
The challenge is that enterprises have a systemic view of the world. They buy systems to do things and all of those systems have their own paradigm about what the world looks like. But it’s a paradigm of that system.
If you’ve got an insurance policy with an insurance company, do you, as the consumer of that policy, care how many systems the insurance policy uses to keep track of that? They probably have a setup one, a risk one, a claims one – all very systemic. There’s no focus on the asset of the elements that the customer understands. The data for your insurance policy is smeared, duplicated, wrong, and generally messed around with across that systemic view. Bits of it are in the risk register, bits of it are in the customer details, bits of it are in claims. Where is the one place that anybody can go, as the consumer, and say this is my policy, I want to know about that policy.
You have the same structural problem when you look at modern manufacturing and the servertisation business model, where you have a mix of static systemic data plus real time usage data coming through. If companies want to manage the battery performance in their electric vehicles for example, it becomes more difficult when the car leaves their factory. They want that data because they want to know about that battery in their vehicle: Where are they going, what they’re doing with it and how hot it is so that they can maintain a relationship with it. However, people are losing track of that data.
What would you ask a client to do, or what would you offer to do for them, to make the integration process easier?
Mark: For Iotics it’s about working out the model that you need, picking the objects of interest and the Digital Twin you want to deal with. From that you can define semantics of that twin: What is its classification? What are its relationships with the other twins? And then you want to model the data that the twin has, such as temperatures, pressures, volumes or time series of data over time.
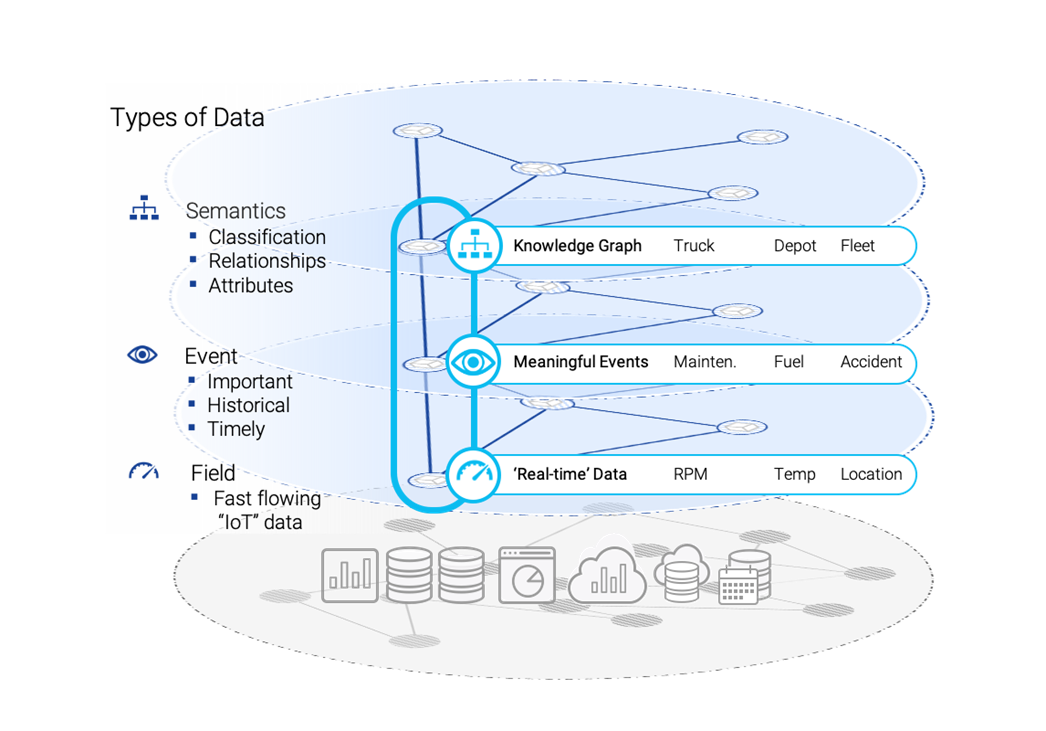
Breaking it down, there are three levels:
- Semantic knowledge graph at the top
- Event-based data. Sitting under the knowledge graph are important historical events: When a policy opened, when/what crash happened, claim made, Risk Registered. Elements that sit across the timeline of that event that come from many different sources.
- Ephemeral data: Temperatures, pressures and volumes that you actually don’t care about because most of the time they are fine. It is only when something goes to a place where it’s not supposed to, or reaches the temperature that it’s not supposed to, that you start to care about it.
We will happily stream ephemeral data but primarily you want to capture the event-based data and we offer to improve the ontological relationship metadata at the top so that you can query things easily.
What do you see as being the key motivating factors that you’re able to use to influence companies to make their data or data systems available?
Mark: A good motivating factor is when there is a fair exchange for their data, it’s not seen as robbery. The best real-world example I can give for that is in the rail industry: Rolls-Royce make power packs which go on trains, these trains are leased to operating companies, and these companies run on Network Rails’ tracks. There’s quite a lot of people in their ecosystem and they have the data.
Initially Network Rail didn’t see the problem with keeping their data or needing other data. Then we asked them to list one of the problems they have. The first problem they listed was having spikes in the electricity supply on the overhead cables that are found by running a special train along the line that looks for spikes. By pointing out that the Hitachi trains that whizz up and down their lines all day are likely to experience those spikes, and that they could give them that information, got them more interested. The world is run on enlightened self-interest so as soon as they saw that someone else’s data is useful to them and their data is useful to somebody else then they will go for it. It’s the same plimsols example: I’ve got your plimsolls, you’ve got my plimsolls. Let’s swap them over.
David: So you’re acting as a broker between companies to find the motivation for both that hopefully helps other people in the in the future as well?
Ali: That brokerage doesn’t have to be like real estate brokerage where you uncover your self-interest, negotiate it, and then come to apoint where you’re justfocusing on what you care about. The knowledge graphs themselves and how everything interrelates can evolve over time. And what that means is that the negotiation is relatively easy because you’re not asking in a kind of catalogue way to show everything simultaneously.
The plimsoll example is slightly flawed in that it implies it is an all or nothing: Either give the plimsoll or don’t. The way we interact as humans isto slowly build trust with each other: I tell you my name,you tell me your name. Where do you work? What do you do? We grow a rapport to the point where it needs not much more than an introduction and then people canstart iteratively sharingtiny bits of information on which you can start building. It’s not long before you find that people are divulging far more than they might have done at the beginning.
For example, the rail ecosystem started by being totally open with Network Rail and talking to them: You have already publicly shared these bits of information. We’re going to use those and we’re telling you that we’re using them so that you’re aware.This is data that’s already publicly available and we’rejust making it available through that ephemeral into the event to go in to the knowledge graph. By starting with what they’ve already made available you can develop a wider sharing strategy from there.
What are Iotics’ thoughts and approaches to the security and trustworthiness of data?
Mark: The basic principle in Iotics is that the twin is in control of his own destiny. The twin is publishing data for other people to consume so it decides what it wants to publish, it decides when it wants to publish it, and it decides who can receive it. It’s about brokered interactions.
As a result, our other principle is that you can’t broker that interaction by talking to the twin itself. I can’t just ask you what the time is on your watch, you have to publish that to me. And that negotiation is done by a third party, not by you and me talking to each other. So, there’s a virtualization and separation of those things and the brokered interaction is one of the very key parts of our security model.
Of course, we have other measures like encryption and signing elements off so that you get the more tamper-proof versions of it. As our product evolves, we are moving towards decentralised identifiers, which is a W3C Standard, and also to verifiable credentials. This means you now have a proper cryptographic way of defining and proving identity and then you can unequivocally relate actions in the system back to an owner or an owner of that public private key pair.
David: Therefore, an organisation or an individual, who’s in essence the data owner, has a fine-grain control of what they publish and who to?
Mark: Yes. The other question you alluded to is veracity and that is a tough nut to crack. At Iotics we can say this person sent this data and nobody’s messed with it until it got to you. We are also trying to tackle the tough question of: Once I have the data, can I trust the data that sent to me is any good?
Ali: An interim measure you have for veracity is purely by initial checks and balances: If you start to pull data from across multiple systems, sources and users, initial validations can be done before you start modelling the events. Individual Twins and composite Twins are made up of multiple sources. You can at least start to, with the controls, identify outliers. If someone is seeing a temperature that is many degrees of magnitude higher or lower than surrounding temperature gauges, you have a clear indication that there is something that needs to be looked at.
Mark: A real world example of that can be seen on a production line where some of the machines had recorded they had 200 million operating hours. I don’t know how long that is in days, but it’s probably before the invention of the electric motor, and they’ve realised that they’ve recorded maximum integer (Int Max) signals from the sensor. Probably the safest principle in IoT is you can’t trust anything. Would you trust a temperature sensor that said, it was 20 Celsius? Even as a scientist you’d put error bars on that. So how big are those error bars? If it says it has got 200 million operating hours, then there’s some pretty big error bars really isn’t it?
Are there any final thoughts would like to like to share?
The one thought for me is that a lot of people say Semantics is a dead end. People say it will never work. Nobody will ever agree. It’s just another standard. But what I feel, defined from my experience, is that some semantics is so much better than none, and it does not actually matter how brilliant it is because at least it’s something. If I sent you ENE as a wind direction and then told you what East North East meant in a semantic way, that’s still better than just sending you ENE isn’t it?
One the philosophies at Iotics is that metadata is free and data costs money. This means you can lay out what data you’re going to send, this is where you can find and “buy” that data, brokering the interaction to it. Then when you send the data you can just send the raw data to avoid bloating the payload with all the semantics, therefore sending the semantics out of band because if we’ve agreed that it’s alright to have the data then you might as well have the description of that data as well.