Last Week…
We looked at Humancentric Digital Twins from the perspective of Virtual Reality. We saw how humans, are not only affected by, but can have an active say in the end product
This week…
We are focusing in from Digital Twins informed by humans to Digital Twins about Humans in the spaces they live in.
What could simulations of the microscopic details of our body, from moving your ankle to sneezing, mean for future living? This week’s expert He Wang gives us a look into the world of crowd simulation…
Our Expert
He Wang (pictured centre) is a Lecturer at the School of computing at The University of Leeds. His expertise is on computer graphics and computer vision, and nowadays he is focusing on machine learning and applied machine learning within those fields of expertise. Aside from lecturing and research, He is the director of a program called a “High Performance Graphics and Game Engineering” which runs as a degree program at undergraduate and masters level, where they teach people how to make games, focusing on the hard kind of skills which comes from mathematics, programming and physics. He is also the academic lead in artificial intelligence and visualization in the newly established Centre for Immersive Technology at Leeds, as well as closely involved in other interdisciplinary themes like VirtuoCity, who we heard from last week.
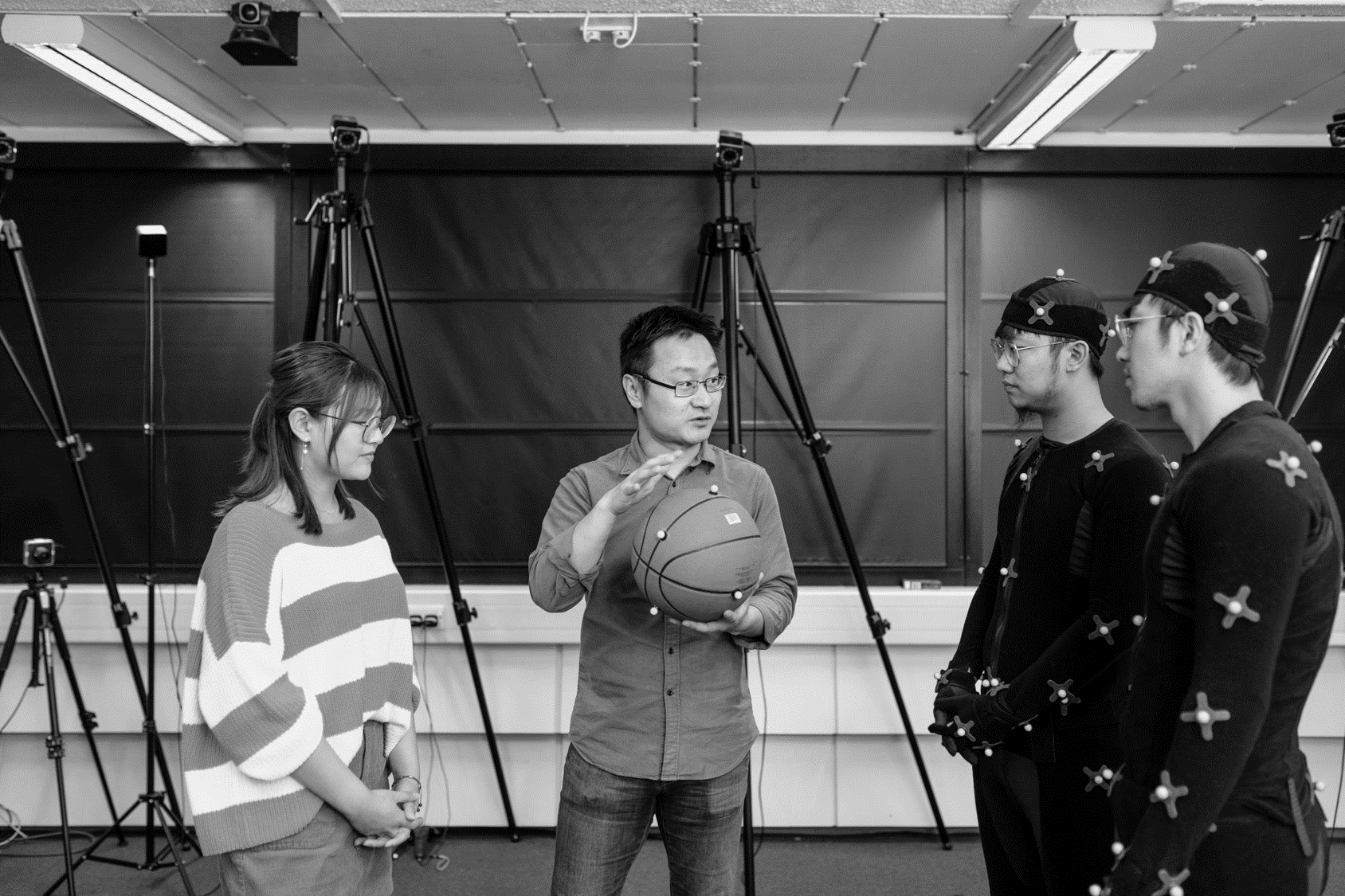
He Wang’s research expertise is closely related to Digital Twins in terms of 3D visualization and Crowd simulation and today he sits down with Slingshot Founder David McKee to discuss what Digital Twins could mean to his area of research in crowd simulation and what this could mean on a microscopic level.
What is your perspective on Digital Twins?
Co-Dependent Species
In my mind a Digital City consumes the data from the ever-changing physical city. So the two cities are like co-dependent species, as the digital city would consume all the data that is generated in the physical city. So that’s like a food provision for the digital city. The digestive system of the digital city would be:
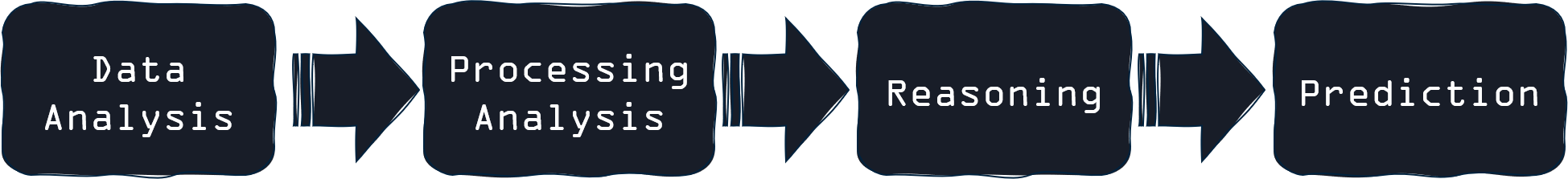
Then the outcome of that would be to for example, inform the decision-making seen generally in the physical city.
Microscopic Simulation on an Individual Level
There are in general two kinds of Crowd Behaviour Researchers within the field of engineering or Urban Analytics: the first type is only interested in high level statistics. They can do crowd simulation or crowd behaviour modelling, but they are mainly interested in clusters and high-level statistics like population density. I reside in the second type, which is what we call microscopic simulations.
In my crowd modelling practice, every single person matters. The level of detail that I go into as I try to model humans goes all the way down to individual body motions. For example, if you’re walking, something as small as your arm swing will be important to me. But that will not be as important to people in Urban Analytics where they only have to treat each individual as a 2D particle moving in a big landscape.
From this perspective I see residents, or space users as I would like to call them, as a centre or one of the many central units that would have generated data for a Digital Twin and therefore should be given priorities when it comes to decision making and policy making
Futuristic Scenario Modelling
So the whole idea is to make decision-making human centred, which could impact how our city looks and behaves in the future. Let me give you a futuristic example:
- You are in Leeds station, you are checking out the information board to see whether you’re train is late or not.
- Then you notice that there are pillars, benches, cafes, shops in this big atrium space.
- Then suddenly, you notice that all those pillars and walls can move!
Walls and pillars can now move easily in the future and they can be controlled by AI driven methods. That would allow you to optimize the space configuration to facilitate the human activities there. To make that happen there needs to be a collective effort consisting of certain people:
- Structural Engineers: They can decide what are moving and how they can move.
- Policymakers: They manage the space in a certain way to achieve certain goals. For example, when the lockdown for COVID-19 is lifted to allow the economy to recover, we will have to face the situation where we have to manage the risk but not be able to eliminate it. In that situation you need to regulate people’s behaviours: where they walk, how far they should stand from each other, how long they are allowed to stand in front of the information desk for example, all these kinds of policies.
- Space managers that deal with all the day-in-day-out activities.
- Crowd Behaviour Experts: That’s where I come in. For example if you have an infectious person then this person’s behaviour is directly deciding whether there will be virus transmission between people, If so, how fast? How dramatically would that be? So that means when you model crowds, you need to be able to also model each individual’s behaviours.
This example would be my ideal take on what a Digital Twin could be doing for us in the future.
Thinking very specifically in terms of individual people’s behaviour, what do you see as some of the key challenges in accurately simulating enough behaviours as there is an infinite set.
That’s a very good question. In one sentence you hammered multiple nails in my field which we haven’t been able to solve completely. The three main challenges for me right now are:
- Data Acquisition.
- Data Processing and Storage
- Explainable Modelling.
Data Acquisition
Modelling Subconscious Behaviours
In most of the existing work in crowd simulation, you probably have noticed that it treats individuals as 2D discs. That’s a massively overly simplified version of humans, making it not so useful in situations like COVID19, which is the first concrete challenge. We need to be able to model at least the 3D low level motionslike steering, acceleration, deceleration, arm swing, leg swing, the low level behaviours, which we probably don’t think of in our brain but just subconsciously do.
Capturing Sufficient and Accurate Data
The high-level behaviours are also hard to crack because in traditional empirical modelling, people can summarize people behaviours into categories, then use reasoning and logic or even the simplest finite state machines to predefine all the behaviours. The challenge is that many rule-based systems don’t capture enough information to be able to do accurate prediction. They can simulate realistic behaviours in general, but it is very hard to use them to do relatively accurate predictions for specific scenarios. For all the machine learning methods, including Deep Learning, we find that we can have a model that has enough data consumption capacity to learn complex behaviours but do not have enough data.
Data Processing and Storage
The next challenge, especially for my type of research who are interested in individual motions, is our need to consume large amount of data. The sensor network out there is not enough at the moment, it’s not covering everywhere and most of the time it doesn’t track at the level of detail we require. Secondly, even though we can track we still need a mechanism to distil that data to remove any irrelevant information because the data size is going to be huge. Only after all the data has been processed and stored appropriately can we begin to model.
Explainable Modelling
The biggest challenge is that you want your model to be explainable. The old explainable diagram of research can explain things but cannot take much data in. Ironically, the newer methods can take a lot more data in but they’re not explainable and humans do not trust these kinds of black box systems. So, a combination of both needs to be attempted at least to address the explainability issue in crowd modelling.
If we look at the first of those challenges, if you could have any type of sensor possible, what would be the types of data would be looking for?
Treating all the humans as my Lab Rats. OK that’s a wrong thing to say but in my ideal world I can attach sensors to people directly to see what they see, what they feel, and their full body motions. I’m talking about full body motion, not only a point in 2D space, and I would want to know when you swing your left arm while your swing your right leg.
Of course, that’s not going to happen. So a less accurate, but more feasible way, is to equip spaces with all sensors like video cameras and Wi-Fi stations, maybe even using people’s mobile phones if possible. So all the sensor data can be used to infer people’s activities. We’re only talking about low level activities at this point. When you do data fusion at that level you might be able to get a full picture of low-level motions, but the current situation is most spaces are not sensorised at all.

How do you see techniques such as State Machines and Markov Chains fitting into building Digital Twins?
Low Level Decision Making
People have been using the Markov Decision Processes to model the low-level decision-making processes for many years. In the context of reinforcement or statistical machine learning, you can come up with a model but it’s very hard for the model to consume large amounts of data. This is before deep learning. It’s really difficult to capture all the heterogeneity in the data.
Deep Learning for Big Data
what we are doing right now is to see whether we can leverage both kinds of methodologies (Reinforcement Learning or statistical machine learning, and Deep Learning), by combining the data capacity of deep learning with the explainability of traditional statistical machine learning methods like Bayesian networks or reinforcement learning. There has been some attempts in the direction in theory, and applications. For example, deep reinforcement learning has been used to play go against humans such as Alpha Go and they’re really good at it. But again, a lot of them in my opinion are used as an optimizer to find the best strategy to carry out actions instead of being able to explain why people do that.
The Missing Pieces
Explaining why people are doing what they do remains a research challenge. Let’s use the train station as an example: If you see a surge of a flow from the front entrance to the ticket office then to information desk then to the ticket office again then to a platform. You can model it by reinforcement learning. You can then observe that 20% of the people in this surge went to the information desk and then went back to the ticket office before going to the platform. But you won’t be able to understand what caused it for each person in the surge.
As humans we can intuitively understand or interpret some of it: Maybe these people really want to get a train, but they got confused? That’s why they’ve gone to the ticket office first and then they had to go to the information desk to gather more information then go back to the ticket office to buy a ticket and then wait for the train on the platform. Or they could be stressed out that their trains were cancelled? So, they had to rush into this station, then got tickets to board a new train. All the high level inferences are not there and the space managers will need to know it. That’s the key difference the model explainability can bring.
You mentioned explainability and understandability. What do you see as the big opportunities and techniques you think would be the right way to approach and create an explainable solution in your field?
The Challenge
Data bias is a really complicated issue. I know that back in 2019 Georgia Tech University published a paper investigating the systematic bias on pedestrian tracking algorithms: They found that self-driving cars may be likelier to hit black people than white people Looking at this example it shows there is no good automatic way of avoiding data bias so far.
Tapping into Cultural Differences
In my area where you model a crowd, personal space is a big factor. Personal space is very different in different cultures. In highly populated countries, people tend to be used to staying very close to each other. But when I first came to this country and saw people queue in front of a bus stop, it was a real eye opener for me, because each person stood around 1 1/2 meter away from each other and then naturally they formed a queue. Although there were only 5 or 6 people it took a lot of space on the street. So I suddenly realised that personal space is big factor here.
Mapping the Big Picture to the Smaller Details
There are lots of other high level factors that we need to understand, even if you don’t model those high level behaviours, as they influence the low level decision making. The space will decide the density, then the density will influence greatly on the velocity with which people could move, which will further influence the overall efficiency of the transportation system. I’m not only talking about the differences between different ethnicities but also between different cultures and different cities. In my area I don’t see that as a problem of modelling rather than a problem of what data is available to use. So if the bias exists in the data already, there’s no good way to automatically make the models to realize that. So it means again, this goes back to your data collection question, if we’re talking about one city, you cannot avoid the bias: If we were talking about multiple countries, we might be able to.
If you were to give a definition of a digital twin in one sentence, what would it be?
A Digital Twin of a city is where the digital twin of the residents live a couple of minutes ahead of you in time.
This is more of a description of a Digital Twin for me rather than a definition. I try to interpret Digital Twins in terms of its functionality in prediction and use that as a description. I do believe that different people will have different definitions.
Given that description, what would you see as being the biggest and or craziest impact that you think a Digital Twin could have?
The biggest impact for me is it could save lives in situations like stampedes.
The craziest impact is it could one day transform our city into a big transformer. And the transformer will keep transforming itself to facilitate the predicted behaviours of humans.
David: So it’s really about creating an Organism. Making it organic
Organism, that’s a very good word because, remember I mentioned that the digital twin and the physical city are like two co-dependent species? There I see the Digital and Physical twins co-evolving in time.
Any other comments or thoughts on digital Twins in general?
I’ve noticed that a lot of academic people have been talking about this Digital Twin idea, but I would like to raise this research vision onto the level of Research Challenge and Global Challenge, because I don’t think this is feasible in one domain. It has to be an effort of all domains and all countries in my opinion. This should be in the UN discussions instead of only being talked about at the University of Leeds.
More in the Series
- What are Digital Twins today?
- Humancentric Digital Twins
- Personal Digital Twins
- Agent-based Modelling for Digital Twins
- Digital Twins and Decision-Making: Leeds City Council
- Digital Twins and Decision-Making: Urban Regeneration
- The Role of Simulation in Decision-Making
- Investing in Digital Twins
- End of Open Plan Offices? Smart Solutions for a Safer Office
- Data Insights, Digital Twins and Dashboards
- Digital Twins for Beginners
- Series Summary